Consensus & lock services
When multiple machines must agree on one truth — which replica is master, who holds the lock, what config is current — you need a consensus algorithm. The cost of getting this wrong shows up in real-world outages constantly.
Chubby
etcd
ZooKeeper
5 replicas, only 1 active — pick which one safely.
Everyone agrees on the same current values.
Replicas know who's primary at any moment.
The data that must be consistent.
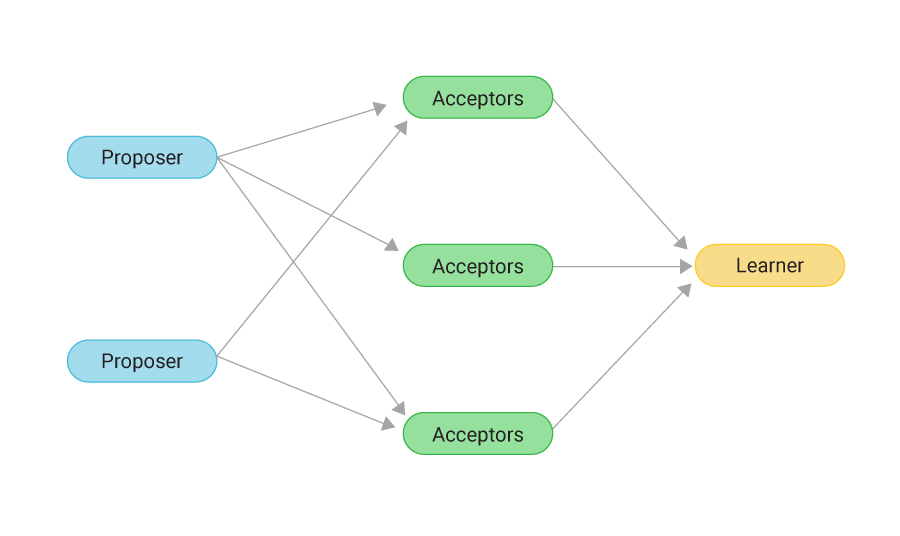
Multiple processes need to agree on a value despite failures. Proposers propose values, Acceptors vote on them, Learners receive the agreed value. The algorithm is robust against network partitions and failures — distributed storage stays consistent as long as a majority of acceptors can still talk.
// you don't usually implement paxos — you use a lock service that does. raft is a more recent, simpler algorithm with the same guarantees.
If you've ever read a postmortem that says "X became unavailable when ZooKeeper went down" or "the etcd cluster lost quorum" — this is why.
Lock services are a single point of failure with cascade potential. They're replicated for exactly that reason — but quorum loss (e.g. 2 of 3 nodes down) takes the whole thing offline.
A team running self-hosted Kubernetes has 3 etcd nodes. One is down for maintenance and another fails. What happens?
// pick one to verify